For one reason or another, myself and my colleagues spend quite a lot of time watching people program. We do this because we think that a very important challenge for the beginner software engineer is learning how to build a program, not just what code is required.
I could talk about that for hours, but it’s not important for this post. What’s important is that we watch a lot of videos and give a lot of feedback. This can take a long time, particularly if you are inexperienced in doing this.
One thing that might help is a way of labelling particular moments in a video as worthy of attention. The natural approach might be to install some special software on the learner’s computer to capture key moments and line them up.
However — I had an idea that the videos contain quite a lot of latent structure. They probably use only a small range of fonts. They are likely not terribly compressed. They are screen recordings so no angles to worry about. We don’t need to do this in real-time. In principle it shouldn’t be so hard to OCR the videos and then search them for test runs and other such things, which we might then label.
I was… not entirely correct, but not a million miles away either.
I got as far as a proof of concept for extracting test suite passes and failures
in a 15m video. The video isn’t entirely contrived, but it’s fairly friendly.
Take a look at the proof of concept here.
I’ll tell you about how I did it:
Step One: Extract Frames
Probably you could OCR videos directly, but no one seems to do it. Instead they extract individual image frames from a video and run OCR on those.
I did this with ffmpeg and a node library called fluent-ffmpeg. You can see
the code
here.
Note that I also did some post-processing. OCR is typically designed to work on
high-resolution document scans, not on smaller but more detailed screen
captures. As such, I scaled to 200% which seems to work best.
I also experimented with altering contrast and removing colour. It didn’t seem to help much but probably worth keeping in the toolkit.
I extracted one frame per second which is enough for our purposes. Could probably go less. I read somewhere that the way I’m doing it here is not the fastest possible, but it’s fast enough.
From that step, I got a directory of images like this:
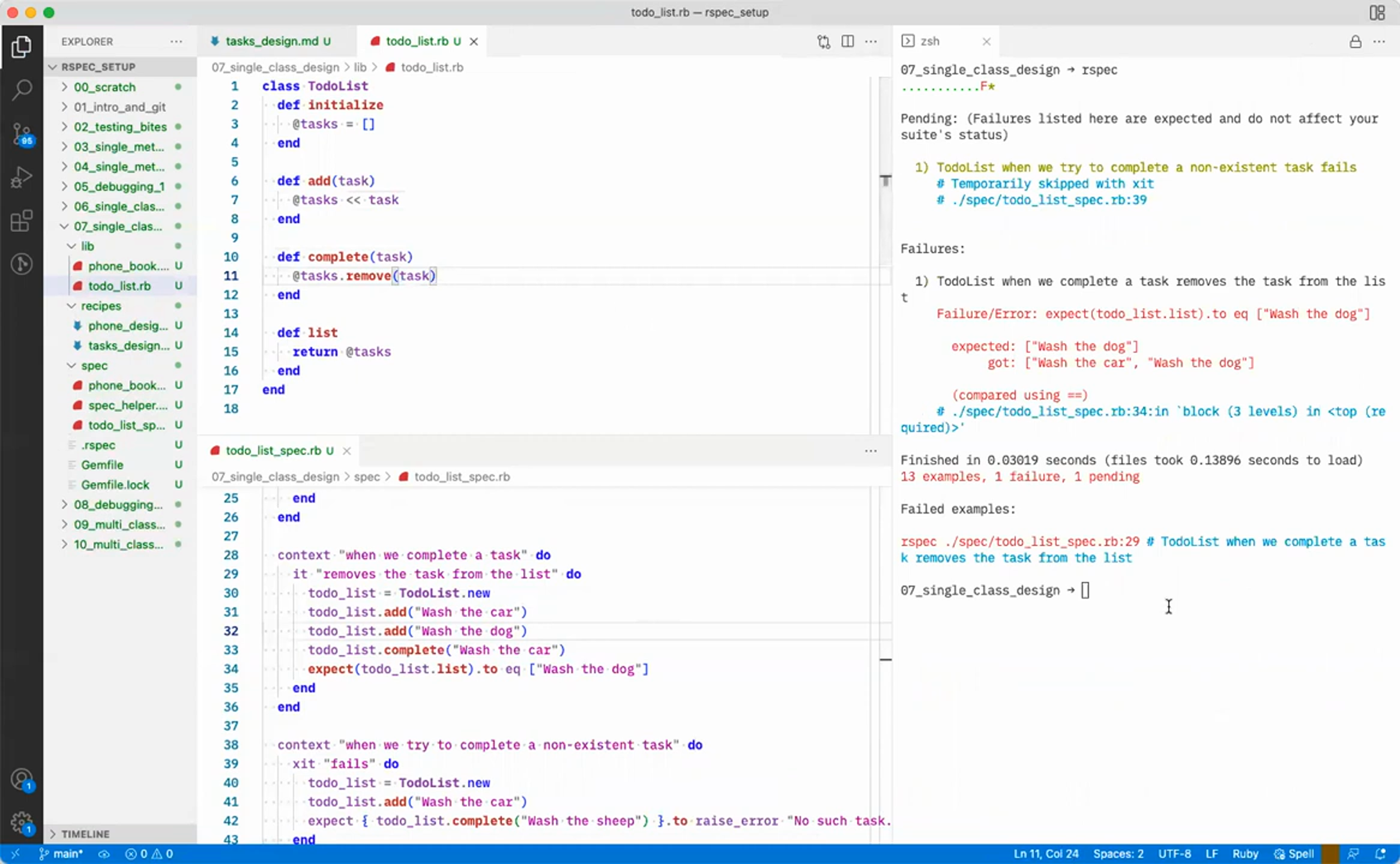
The source video is a bit blurry but that’s sort of useful for our purposes.
Step Two: Optical Character Recognition
After some investigation I decided to use Tesseract OCR. They have a command-line tool which is very useful to play with, but there’s also handily a pure JS version which I switched to for my tool. It even runs in the browser! We’ll use node but it’s pretty cool to see the demo on their website.
You can see my code here.. Tesseract has all sorts of options which in this case I didn’t use but are worth fiddling with.
Here’s an excerpt of the output for the above image:
v spec a 16 end got: [“"Wash the car”, "Wash the dog"]
|ponecbookc. U 17 end (compared using ==)
@ spec_helper.... U 18 # ./spec/todo_list_spec.rb:34:in 'block (3 levels) in <top (re
@ todo_list_sp... U quired)>'
goean - @ todo_list_spec.rb U e i
Gemfile v Finished in 0.03019 seconds (files took 0.13896 seconds to load)
Gemile.Jock v 07_single_class_design > spec > @ todo_list_spec.rb 13 examples, 1 failure, 1 pending
> 08_debugging... * i: .n;"d Failed examples:
> 09_multi_class... *
> 10_multi_class... * 27 rspec ./spec/todo_list_spec.rb:29 # TodoList when we complete a tas
28 context “"when we complete a task" do k removes the task from the list
29 it "removes the task from the list" do
30 todo_list = TodoList.new 07_single_class_design » []
It’s hardly executable, but we’ve got 13 examples, 1 failure, 1 pending in
there! Which is a nice clean version of what we’ll need.
I dumped all the OCR’d text into a big JSON and did the rest in the browser.
Step Three: Extracting Events
For this proof of concept I wanted to focus on intersection of simplicity and power. It would have been super cool to track all test runs, but it’s more complex. I settled on just labelling when the test suite was red and when it was green. In my work we train a lot of test-driven-development and so observing learners run the red-green cycle is useful to us. Even a way to easily notice if learners are running an ‘write all the tests and then the code and then run the tests at the end, hoping it’s all green’ would be very useful.
I developed a pretty janky pipeline to do this. Code here, but description below:
-
Select all the frames that contain ‘Finished in’ or ‘seconds to load’.
rspecoutputs these at the end of a test run so this helps us filter. -
Select all of those which match
/(\S+) exa.ples?, (\S+) .ailures?/g.
Why is it missing random letters? Those were the ones Tesseract most often failed to match correctly, so I made it robust to those. The actual regex is a little longer. Why\S? You’ll see. -
Extract the numbers of examples, failures, pending, and errors.
This is our provisional ‘event’ for that frame. There’s a lot of munging here to ignore frames where the OCR result is impossible (e.g. more failures than examples) or weird characters. Turns out0is not trivial to detect, often being matched as © or@or even8! I had to handle all of this smartly. -
De-duplicate events.
If one frame shows up 8 examples 2 failures, and the next frame does too, that’s not really a new event (probably). We compress them down into a sequence of unique events, but keep ahold of the number of frames that event represents, because… -
Discard one-off ‘noise’ events.
A little surprisingly (to me) the odd frame will ‘flicker’ and match a0as an8or something. As a result, I decided to filter only on events that stick around a certain number of frames. In the proof of concept this is just 2 frames but on other messier videos it has been as high as10. The tradeoff is that you do accidentally discard real events if they show up on screen for just a few seconds. -
De-duplicate events (again).
After the above process, we can end up with more duplicate events, so we merge them together. -
Return a (mostly) clean sequence of events!
Great!
I’m not a data engineer, or analyst, but I guess the above is a little like what they might be doing.
After this, it’s over to the UI.
Step Four: Render
This is mostly ordinary UI dev stuff, but I thought worth commenting on a couple design choices.
-
Timelines
I considered using a youtube-style timeline here, and it might still be a good idea, but horizontal space does tend to compress information and mind that for the person reviewing the video the events is their key navigation aid. We want it to be as rich as possible to help them work. As such, it’s to the right. -
Seeking
There’s a decision to be made here — when the reviewer clicks an event, do they want to see that event happen (i.e. before the event) or the result of that event (i.e. after the event). I’ve picked ‘after’ here because I like that the reviewer can flick through the events and see the results on the screen. They may not even need to watch at all!
What next?
-
Trying this on more realistic videos.
I have experimented, and the results weren’t irredeemable but they were definitely worse. I think this is down to editor theme (dark mode is, I think, harder — can we just invert?) and editor font. Tesseract has real problems with the default VS Code font — and actually any font where the 0 has a cross-bar.However I’ve made some early attempts to tune Tesseract to handle particular fonts and it has worked quite well, solving most problems. As we’re going to have a pretty good idea the range of fonts people will use I think this will be a good solution.
-
Build a live environment.
There’s typically a delay of at least a couple hours between submission and review. This is more than long enough for a system to work through without worrying too much about performance. So it’s a matter of putting together a pipeline I suppose! The tool isn’t so far away from this right now handily.I did consider whether to use a cloud API like Google’s Vision API. However, these are pricey — $0.15 per minute! A bit cheaper to extract frames and then OCR those though, probably $0.08 per minute?
However, the accuracy does look to a few steps better, so probably worth looking into if we find something worth building properly.
-
Make it label other things.
What else could be labelled? There are a few things that might be interesting. How often are tests run? What error messages is the coder encountering and how long are they stuck on fixing them? Does the learner spend ages working on one specific area of the code? What debugging tools do/don’t they use? Are there any code-level antipatterns worth picking up on?Tools like this could also be useful for augmenting teaching videos too.
Ultimately I’d love if a tool like this could reconstruct the codebase being worked on as it is built up — even partially. That’s a big project — but nothing really impossible about it!
Feel free to reach out if you’d like to talk about it.
If you liked this, perhaps you will like other things I make. Like my newsletter K.log, or my tweets at @neoeno, or my website — you're on it right now!